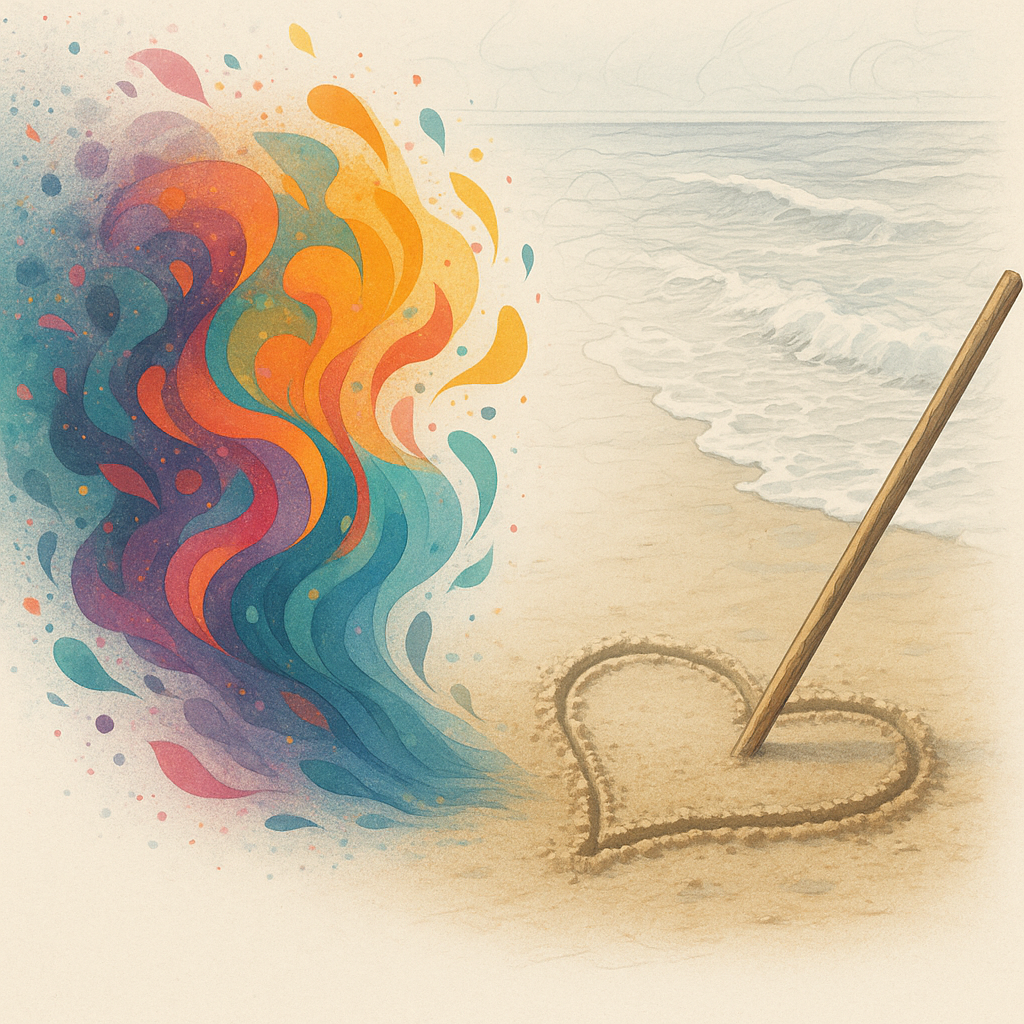
רוצים להכשיר את העובדים שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להישאר מעודכנים? הצטרפו לקבוצת הווצאפ שלנו
רוצים להכשיר את העובדים שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להישאר מעודכנים? הצטרפו לקבוצת הווצאפ שלנו
רוצים להכשיר את העובדים שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להישאר מעודכנים? הצטרפו לקבוצת הווצאפ שלנו
רוצים להכשיר את העובדים שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להטמיע AI בחברה שלכם? בואו נדבר
רוצים להישאר מעודכנים? הצטרפו לקבוצת הווצאפ שלנו
למה זה מרגיש לכם כבר מוכר?
הרי זה קרה לכם: אתם יושבים מול דף חלק, מציירים משהו, מוחקים, מוסיפים קו, ושוב מטשטשים עד שהתמונה מתיישבת בדיוק כמו שדמיינתם.
אותו מחול מסודר של הוספה-מחיקה משוחזר גם בכלי AI ליצירת תמונות – רק שהם עושים זאת מיליארדי פעמים בשניות.
אז מה זה בעצם מודל דיפיוז'ן?
מודל דיפיוז'ן הוא שיטה שבה המחשב לוקח תמונה מלאה, מפזר עליה "רעשים" עד שאי-אפשר לזהות כלום, ואז מנסה להחזיר אותה לאט-לאט למצב ברור ומשמעותי.
בזמן החזרה לאחור הוא לומד אילו נקודות רעש שייכות לחתול, לשמיים או לבדיוקן אנושי, וכך מבין איך לבנות תמונות חדשות מאפס.
כשמבקשים ממנו ציור כלשהו, הוא מתחיל מגוש רעש אקראי ומסיר ממנו את הנקודות הלא מתאימות שלב אחרי שלב, עד שהקווים והצבעים הרצויים מתגלים.
כמו ציור בחול ים שנשטף בגלים
דמיינו שאתם מציירים לב על חול רטוב בחוף.
גל מגיע, מטשטש את הכול, ואתם מעבירים מקל ומחדשים את קווי הלב לאט-לאט, כשהזיכרון של הצורה המקורית עדיין בראשכם.
כל מעבר גל מטשטש עוד קצת, וכל מעבר מקל מחזיר קצת פרטים – עד שהלב חוזר להופיע יפה וברור.
מודל דיפיוז'ן עושה אותו דבר: הרעש הוא ה"גל" שמוחק, והשלבים ההפוכים הם ה"מקל" שמחזיר את הצורה.
איך DALL·E והחברים שלו עובדים עבורכם
כשאתם כותבים בקשת טקסט כמו "חתול סקייטר בקומיקס יפני", האלגוריתם מתרגם את המילים למעין מפה של רעיונות – סכמת צבעים, סגנון קווים, תנוחת הגוף.
הוא מתחיל מתמונה רועשת לגמרי ומתקן אותה אלפי פעמים, כל פעם קצת, תוך בדיקה האם היא כבר נראית קרובה למפה שהופקה מהטקסט.
בכל תיקון הוא מסנן גרעיני רעש שלא מתאימים לחתול או לסקייטבורד, ומוסיף פרטים שדווקא כן צריכים להיות שם, כמו אוזניים משולשות או גלגלים זוהרים.
השלבים נעשים במהירות אדירה, ולכן התמונה גולשת אל המסך שלכם כאילו נוצרה בבת-אחת, למרות שהיא תוצאה של אינספור צעדים קטנים.
התהליך הזה מאפשר לקבל וריאציות רבות: שינוי קל בטקסט או בלחיצה על "רענן" מפעיל שוב את שרשרת הסרת-הרעש ומוביל לציור אחר לחלוטין.
טיפים קטנים לשימוש חכם
נסחו בקשות מפורטות: ציינו זווית צילום, סגנון (שמן, קומיקס) וצבעוניות כדי לכוון את הסרת-הרעש למקום מדויק.
הוסיפו מילים של "Mood" כמו דרמטי, עליז או חלומי – המודל יודע לתרגם גם רגשות לחיתוך-רעש שונה.
אם פרט חשוב חסר, הקליקו על "רימיקס" או "בקש שוב" במקום לתקן ידנית; צעד נוסף של דיפיוז'ן יכול להכניס אותו בצורה טבעית יותר.
ולבסוף, זכרו שתמיד אפשר להוריד לחלוטין את התוצר וללטש בתוכנה גרפית – מודל הדיפיוז'ן עשה את רוב העבודה, עכשיו תורכם להוסיף טאץ' אישי.
בין הרעיון לתוצאה – למה לפעמים זה נתקע?
כש-DALL·E או Midjourney מתחילים לגרד את הרעש מהבד הדיגיטלי, הצעד-אחורה הראשון עדיין רחוק מאוד מהתמונה הסופית. ברגעים האלה המודל מחזיק בראש רק תמצית כללית של הבקשה, משהו בסגנון “חתול+סקייטבורד+קומיקס”, ומנסה לנחש לאן להסיט כל כתם. אם ביקשתם רעיון עמוס במיוחד – נגיד גם חתול, גם סקייט, גם שקיעה בעיר עתידנית – השלב המוקדם הזה נעשה דומה לניסיון לשמוע שלוש תחנות רדיו בבת-אחת: הכול מתערבב. המודל עלול להיתקע על מבנה אחד חזק מדי, להתעקש על שקיעה כתומה ולהשאיר את הסקייטבורד כרעיון מעורפל בלבד.
אחרי כמה סבבים הדימוי במוחו של האלגוריתם מתחדד, אבל אם אחד הרעיונות השתלט, קשה לשחרר אותו. זה הרגע שבו אתם רואים מסך מלא בעננים ורודים כשביקשתם בכלל סצנת רחוב, או חתול שנעלם לטובת רובוט נוצץ. במילים אחרות, ה”שכחה” שאתם פוגשים היא תוצר לוואי של מאבק פנימי בין רמזי טקסט שמנסים למשוך את הרעש לכיוונים שונים.
הידיים המוזרות והעיניים הלא מסונכרנות
השלבים המאוחרים של הדיפיוז’ן אמורים לטפל בפרטים הקטנים: מספר אצבעות, כיוון מבט, רפלקציות עדינות. אלא שהמודל למד מתמונות רשת שבהן גם לצלמים אמיתיים יש טעויות תאורה, איברים חבויים או משולבים. כשמערכת הלמידה פוגשת עשרות דוגמאות של יד מרובת אצבעות (כפול גלים וצללים), היא לא תמיד מבינה שזה פגם; מבחינתה זו וריאציה לגיטימית של “יד”. לכן, רגע לפני שהרעש נעלם כליל, היא עלולה להשאיר חצי אצבע עודפת או להחליף את הסנטר בעין.
ב-Claude וב-Stable Diffusion רואים את זה בצורה דומה: ככל שהאזור המצולם נדיר יותר בנתוני האימון – כוס שקופה בצילום תקריב, או משקפיים עם שני מוקדי אור – כך גדל הסיכוי שהאלגוריתם ימציא פרט שלא קיים. הוא פשוט לא הספיק לבקר מספיק דוגמאות נקיות כדי ללמוד מהם הגבולות המדויקים של “כך אמורה להיראות כף יד בריאה”.
על הכפתור “Generate Again” ועל זיכרון קצר
לחיצה חוזרת על “Generate” מרגישה לפעמים כמו משחק מזל, אך מתחת לפני השטח קורה משהו מחושב: בכל סשן חדש המודל מקבל “זרע” אקראי שמפזר את הרעש אחרת. זו הסיבה שהצילום החמישי מוצא סוף-סוף את הזווית המושלמת, בעוד הראשון נראה כמו סקיצה מבולגנת. מאחר שהשלבים המוקדמים קובעים את קווי המתאר, אפילו שינוי זערורי בזרע האקראי מגלגל את הסיפור כולו למסלול חדש.
האפקט מוכר גם ב-ChatGPT כשמבקשים ניסוח נוסף ומקבלים תשובה ברוח אחרת לגמרי: אותו מנגנון רנדומלי שומר על גיוון, אבל הוא גם גורם לקפיצות לא צפויות. לכן, אם אתם במרדף אחר קומפוזיציה מדויקת, כדאי להיאחז בזרע טוב שכבר מצא חן בעיניכם ולבצע עליו תיקונים קטנים במקום לפתוח הגרלה כל פעם מחדש.
להפוך את ההבנה לפעולה יומיומית
ברגע שמבינים שהשלבים הראשונים בונים שלד גס והמאוחרים מלבישים פרטים, אפשר לעבוד במודע עם המודל ולא נגדו. התחילו עם ניסוח ברור של האובייקטים המרכזיים ובדקו את התוצאה המוקדמת בתצוגת התקדמות (ל-DALL·E יש אופציה לראות שלבים, וב-Stable Diffusion ניתן לעצור באמצע). אם השלד כבר נראה בכיוון, אל תשנו את הטקסט – העדיפו לכוון את הסשן הבא עם מילים שמשפיעות בעיקר על גימור כמו “high-detail” או “soft lighting”.
כשתרגישו שהידיים שוב מתעקמות, כוונו את האלגוריתם ל”hands close-up” או “anatomically correct” במקום להאריך את המשפט בתיאורים כלליים. אתם בעצם מזריקים רמז חזק שרלוונטי לשלב המאוחר, שם הבעיה מתרחשת. ואם אתם אוהבים תוצאה אבל רוצים אותה בגוון אחר, שימרו את הזרע, העבירו אותו ל-“Variation” והגבילו את דרגת האקראיות; כך תרוויחו רצף תמונות עקבי בלי לוותר על הניצוץ היצירתי.
בסוף, דיפיוז’ן הוא כמו דיאלוג עם מאייר שאין לו סבלנות לשמוע מונולוגים ארוכים. תנו לו מסר ברור בתחילת הדרך, תקנו אותו בעדינות בזמן, והוא יחזיר לכם עולם מלא פרטים שהייתם מתקשים לצייר לבד.


